Использование ABE в Windows Server 2003
Обновлено: 20.05.2026
В сети есть шара files на файловом сервере, в шаре куча папок, щелкаешь на них - restricted... Интересно, что там??? Можно попробовать подобрать пароль...
Знакомо? Попробуем немного улучшить ситуацию.
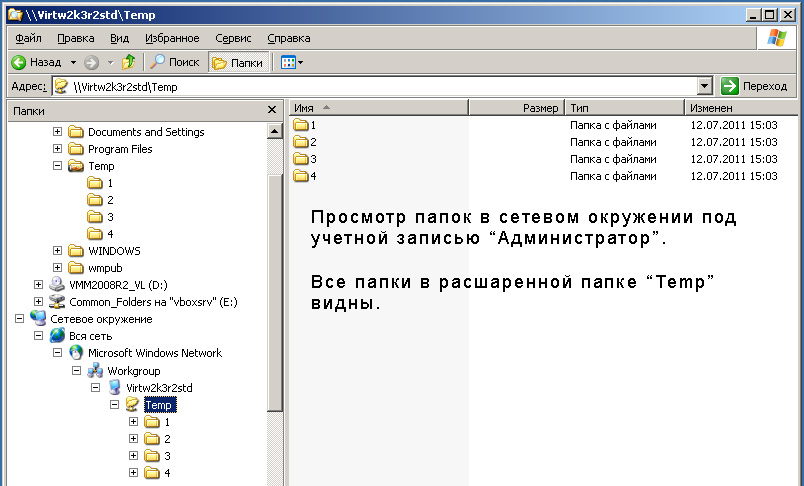
Предположим, в сети расшарена папка Temp с вложенными в нее папками 1, 2, 3 и 4:
+ Temp
---- 1
---- 2
---- 3
---- 4
У нас есть два пользователя: test1 и test2. Пользователь test1 должен иметь доступ к папкам 1, 3 и 4, пользователь test2 должен иметь доступ к папкам 2, 3 и 4. Как сделать так, чтобы пользователь test2 не знал, что в папке Temp вообще есть что-то, кроме его папок?
Вариант 1: сделать отдельные шары для каждого пользователя. Это выход, но если папки 3 и 4 используются совместно? Делать отдельную шару для общих папок? А если пользователей 20 штук? Вот. В такой ситуации Microsoft предлагает использовать Access-Based Enumeration (сокр., ABE).
Access-Based Enumeration
Access-Based Enumeration возможно использовать на Windows 2003 SP1 и выше, Windows 2003 R2. Скачать Access-Based Enumeration можно на сайте Microsoft. Размер 500 кбайт. Установка простая, даже описывать нечего.
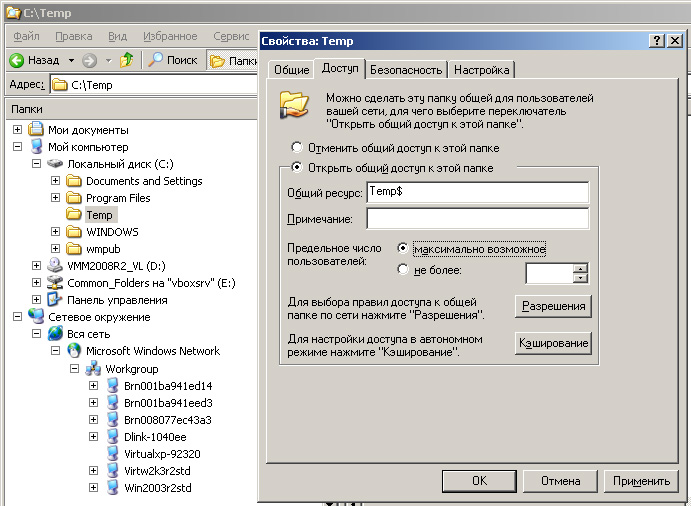
Access-Based Enumeration появляется в виде дополнительной вкладки между вкладками "Безопасность" и "Настройка" расшаренной папки:
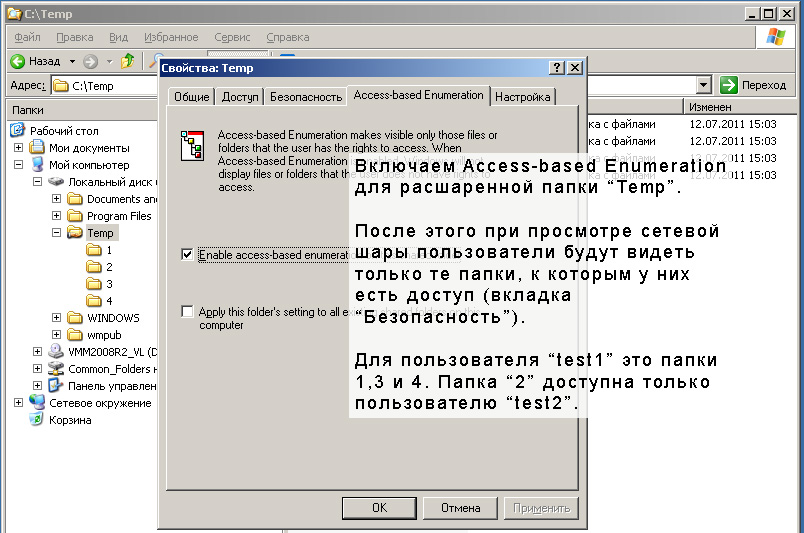
Основная мысль: расшаривается "головная" папка, содержащая все остальные (в нашем примере это папки 1, 2, 3 и 4). Доступ во вложенные папки задается стандартно через вкладку "Безопасность". В нашем примере папке 2 дан доступ только для пользователя test2.
Пользователь test1 не увидит папку 2 просматривая шару:
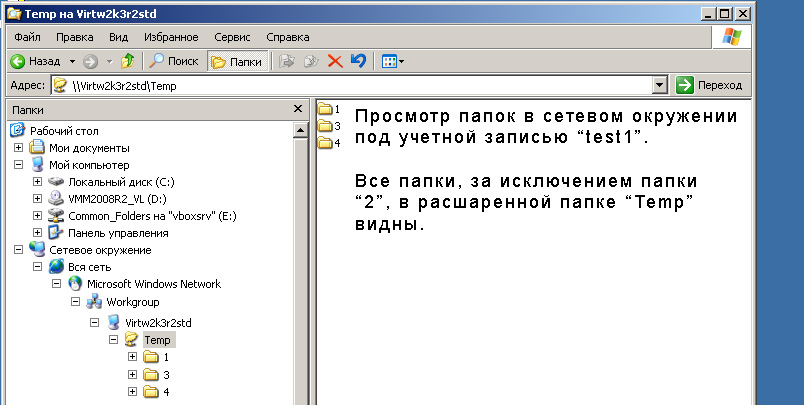
Таким образом не только ограничивается доступ к содержимому папки 2, но скрывается сам факт ее наличия. Т.е. пользователи могут просто не знать, есть ли другие папки в той шаре, с которой они работают каждый день. Точно также можно задавать права не только для папок, но и для файлов. Меньше знаешь - крепче спишь. В нашем случае, крепче спит администратор сети!
Скрыть шары
Обновлено: 20.05.2026
Зачастую в сети расшарено немалое количество папок, среди которых могут быть такие, как buch, archive, backup, private и другие, названия которых говорят сами за себя. И не факт, что пароли пользователей этих "шар" достаточно стойкие. Зачастую это неудобно пользователям (если необходимо, то пароли надо делать сложными). И совсем не факт, что 19-летний паренек сможет доказать стариканамвзрослым и умным бухгалтерам, что пароли надо сделать сложными.
В такой ситуации можно сделать неприлично простую вещь: изменить имена шар, добавив к ним знак $. Например, была шара backup. Добавим к имени шары знак $: backup$. Теперь эту папку в сети никто не увидит. А на рабочем столе достаточно будет сделать ярлык и работать станет немного безопасней :)
Установка Adobe Reader из MSI и применение пакетов обновления MSP
Обновлено: 20.05.2026
Эта статья обновлена в мае 2012 года и принадлежит серии статей про установку программ в Active Directory. Несмотря на обилие текста, сразу смотрите финал (на этой странице) - все слишком просто! Потом читайте спокойно и вдумчиво.
Задача
Подготовить пакет Adobe Reader со всеми обновлениями на текущий момент для установки через Active Directory.
Второстепенная задача: научиться применять обновления в формате MSP (расширение .msp).
Исходные данные
На 28.02.11 актуальной версией Adobe Reader является 10.0.1. Для русской версии доступны AdbeRdr1000_ru_RU.msi и файл обновления AdbeRdrUpd1001_Tier4.msp. Ссылки указывают на директории на ftp-сервере Adobe.
Файлы обновлений в формате MSP для Adobe Reader называются по-разному в зависимости от языка исходного продукта. Для русской версии нам нужен файл AdbeRdrUpd1001_Tier4.msp (а не Tier1, 2 или 3). Подробнее об этом читайте здесь.
По поводу получения msi-файлов могу сказать, что очень похоже на то, что Adobe всегда будет предоставлять файлы msi для установки через Active Directory. Способ, описанный мной здесь скорее всего не пригодится.
Вариант 1: с предварительной распаковкой MSI-архива
Нам будет необходимо подготовить пакет msi (.msi), наложить на него патч (.msp) и скопировать результат на сетевую папку для дальнейшего распространения средствами Active Directory.
1. Готовим MSI-пакет для наложения патча
Это вариант начала 2011 года.
Создадим папку C:\Temp\Adobe и скопируем в нее файлы AdbeRdr1000_ru_RU.msi и AdbeRdrUpd1001_Tier4.msp.
Запускаем cmd и переходим в созданную папку:
> cd C:\Temp\Adobe
Распаковываем AdbeRdr1000_ru_RU.msi в папку Updated:
> msiexec /a AdbeRdr1000_ru_RU.msi TARGETDIR=c:\Temp\Adobe\Updated
Запустится инсталлятор, соглашайтесь и примайте :) После этого в папке Updated будут лежать файлы для установки по сети. Но это пока еще версия 10.0.0. Нам надо обновить ее.
2. Обновляем установочный набор
> msiexec /a c:\Temp\Adobe\Updated\AdbeRdr1000_ru_RU.msi /p C:\Temp\Adobe\AdbeRdrUpd1001_Tier4.msp
Эта команда объединит существующий набор с обновлениями из файла AdbeRdrUpd1001_Tier4.msp.
3. Копируем обновленный набор в сеть
Теперь копируем папку Updated в сеть и распространяем обновленный пакет Adobe Reader 10.0.1 всем пользователям локальной сети.
Собрав все вместе, привожу команды консоли cmd одна за другой, все три!
> cd C:\Temp\Adobe
> msiexec /a AdbeRdr1000_ru_RU.msi TARGETDIR=c:\Temp\Adobe\Updated
> msiexec /a c:\Temp\Adobe\Updated\AdbeRdr1000_ru_RU.msi /p C:\Temp\Adobe\AdbeRdrUpd1001_Tier4.msp
Вот и все. Слов оказалось намного больше дела.
Вариант 2: сразу объединяем основной MSI и MSP-патч
Это вариант начала 2012 года.
Вообще, как показала жизнь, далеко не всегда нужны муки выбора языковых Tier-ов. Например, недавно для получения Adobe Reader версии 10.1.3 я использовал сочетание (все с офиц. ftp) AdbeRdr1010_ru_RU.msi и AdbeRdrUpd1013.msp.
В официальном руководстве от Adobe (см. внизу список литературы) предлагается такой вариант:
Копируете в папку (например, C:\Temp\Adobe) файлы msi и msp и выполняете такую команду:
> cd C:\Temp\Adobe
> msiexec /a [MSI file name] /p [MSP file name]
и копируете все, что в папке C:\Temp\Adobe, туда, откуда через групповые политики распространяете ПО.
Интересный момент (текст далее несколько сумбурен, можете не заморачиватсья, на скрость не влияет и можете смело читать этот абзац наискосок): в папке C:\Temp\Adobe так и останутся файлы AdbeRdr1000_ru_RU.msi и AdbeRdrUpd1001_Tier4.msp, но файл AdbeRdr1000_ru_RU.msi будет уже не тот, что вы скачали с сайта Adobe, а измененный. Поэтому если вы потом вдруг (например, экспериментируя) замените файл AdbeRdr1000_ru_RU.msi в папке C:\Temp\Adobe на оригинальный, скачанный с сайта, у вас обновление не пройдет. Я не знаю механизма работы патчей MSP, но, возможно, в файл MSI "встраивается" ссылка на патч и именно в таком виде они дальше могут взаимодействовать. Я это почему пишу: я все это "пробую" шаловливыми ручками и, создав обновленный пакет, решил заменить файлы с одинаковыми названиями и увидел, что ничего таки не стало вдруг работать :)
Литература
- Для тех, кто предпочитает читать превоисточники, смотрите руководство для администраторов (англ., офиц. сайт Adobe, формат PDF).
- Чтобы знать, в какой порядке ставить обновления, см. соответствие версий и языковых пакетов (англ., офиц. сайт Adobe).
- Список материалов (англ., офиц. сайт Adobe) для системных администраторов.
Прозрачный Squid
Обновлено: 23.06.2021
Зачем нужен прозрачный Squid
Для начала представим, что у нас есть обычная сеть, выходящая в интернет через один шлюз (прокси-сервер Squid установлен здесь же). Предположим, IP-адрес шлюза 192.168.1.1. Все остальные компьютеры в сети получают настройки IP по DHCP. Компьютеры в сети разные, Windows XP/7, Ubuntu, да моло ли еще какие. За всеми не углядишь. Но мы должны считать трафик, ускоряя при этом доступ в интерент, должны контролировать (хотя бы от "дурака") доступ в интернет и пр. Squid обладает широкими возможностями по логированию, ограничению доступа и пр. Поэтому нам нужно, чтобы все компьютеры в сети не могли миновать нашего прокси-сервера Squid. Поэтому нам надо в любом случае направить (завернуть, пробросить) запрос клиентских компьютеров только через прокси-сервер Squid.
Настройка переадресации портов
При обращении клиентов локальной сети к внешним сайтам Squid должен прозрачно для клиента перехватить запрос и обработать его согласно своим правилам - решить, какой контент отдать, логировать ли активность пользователя, можно ли вообще этому пользователю выходить в интернет. Наша задача - сделать так, чтобы на самом клиенте не надо было бы делать никаких настроек броузеров. Клиент просто подключился к локальной сети и уже работает через наш прокси-сервер и НИКАК иначе. Т.е. даже если кто-либо захочет обойти наш прокси, без хитростей ему уже не обойтись.
Переадресация портов в FreeBSD
Если на нашем шлюзе установлена FreeBSD и брандмауэр по-умолчанию - IPFW, то для выполнения этой задачи мы должны на шлюзе установить переадресацию (проброс) портов:
# Redirect to local proxy
/sbin/ipfw add 0170 fwd 127.0.0.1,3128 tcp from 192.168.1.0/24 to any 80
где:
- 0170 - номер правила (в вашем случае может быть любой).
- fwd 127.0.0.1,3128 - куда будем направлять пакеты, - в нашем случае нашему любимому Squid, запущенному на порту 3128 на шлюзе, - ...
- from 192.168.1.0/24 - ... отправленные компьютерами локальной сети...
- to any 80 - ... на какой-либо сайт в интернете
Теперь внимание! Это правило нужно добавить ДО того, как правила NAT (Network Address Translation) получат этот запрос. Объясню немного неакадемично: что делает NAT? В нашем случае NAT изменяет адрес источника (заменяет локальный IP клиента на внешний IP шлюза и запоминает, от какого внутреннего клиента был запрос. Для того, чтобы Squid обработал запрос от клиента, ему не нужно ничего преобразовывать - он и сам с этим справится. Поэтому Squid должен получить пакет в первозданном виде и сам решить, что делать дальше.
К тому же NAT и Squid - все-таки разные вещи, и пакет, адресованный, скажем к 2.3.4.5:80, не содержит информации, как попасть в Squid (на порт 3128 шлюза). И пакет будет обрабатываться только средствами NAT. Squid пакет так и не увидит. Поэтому наша задача - просто отдать Squid-у тот пакет, который отправил броузер пользователя. Объясню на примере части конфига ipfw:
cmd="ipfw -q add" $skip="skipto 5000" pif="xl1" #внешний интерфейс ... # Redirect to local proxy $cmd 0170 fwd 127.0.0.1,3128 tcp from 192.168.1.0/24 to any 80 # NAT $cmd 0200 divert natd ip from any to any in via $pif # Allow keep-state statement. $cmd 0201 check-state # POP3/POP3S $cmd 0325 $skip tcp from any to any 110 out via $pif setup keep-state $cmd 0326 $skip tcp from any to any 995 out via $pif setup keep-state # WWW (HTTP/HTTPS/..) $cmd 0350 $skip tcp from any to any 80 out via $pif setup keep-state $cmd 0352 $skip tcp from any to any 443 out via $pif setup keep-state # This is skipto location for outbound stateful rules $cmd 5000 divert natd ip from any to any out via $pif ...
В конфиге выше запрос открыть сайт сначала обрабатывается правилом 0170, которое заворачивает запрос в Squid. Squid (как и любая другая программа) также выполняет требования брандмауэра - только для него правило 0170 не действует, а вот правило 0350 разрешает Squid отправить запрос в интернет. Для того, чтобы выходить в интернет без Squid, необходимо закоментировать правило 0170. В этом случае Squid не получит ничего, а все запросы броузеров из локальной сети будут обрабатываться правилом 0350.
Переадресация портов в Linux
Если на нашем шлюзе установлена Linux и iptables, то вышеуказанная команда будет выглядеть так:
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j REDIRECT --to-port 3128
где eth0 - внутренний интерфейс.
В остальном смысл переадресаций и пр. аналогичен тому, как это объяснялось для ipfw. Разнятся только правила постороения конфигурационных файлов ipfw и iptables. Пример правил iptables можно изучить здесь.
С этим разобрались. Теперь надо дать указание Squid о том, что он должен обрабатывать пакеты, изначально на него не направленные. Переходим к включению режима прозрачности Squid.
Прозрачный Squid в squid.conf
Теперь дело осталось за малым - настроить Squid в режим невидимки, т.е. принимать автоматически перенаправленные пакеты и обрабатывать их. В разных версиях Squid за это отвечали разные команды. Настройка Squid версии 2.6.* выглядит так:
http_port 127.0.0.1:3128 transparent # Squid работает в прозрачном режиме
Внимательно просмотрите конфигурационный файл squid.conf на предмет дубликатов директив - я потратил два часа времени, обратился на форум за помощью с "нестандартной проблемой", в то время как просто не обратил внимание на то, что первой строкой у меня включался обычный режим работы Squid:
http_port 3128 # Squid работает в обычном режиме
Практически все. Перезапустите Squid, примените правила брандмауэра с добавленной командой перенаправления портов - теперь любой компьютер локальной сети, выходя через наш шлюз в интернет, не сможет миновать нашего ставшего прозрачным для всех Squid. А теперь попробуйте настроить прокси на каком-нибудь компьютере - компьютер не должен получить выход в интернет. Вроде все. Если есть вопросы или советы - комментарии приветствуются, особенно учитывая, что настройка прозрачного Squid и проброс портов вообще "больная" тема на форумах.
Плюсы и минусы
Из плюсов можно отметить абсолютную уверенность, что все запросы на 80 порт (стандартный для веб) будут обработаны Squid-ом. Соответственно, будут логи, статистика для шефа и отсутствие необходимости бегать и руками все настраивать.
Из минусов можно отметить:
- невозможность (по-крайней мере, простым способом) авторизовать пользователей для доступа в интернет;
- если вдруг "упадет" Squid, то доступ к сайтам прекратится. Поэтому админу нужно или быть уверенным, что все будет ОК, или иметь возможность удаленно изменить конфиг брандмауэра, или написать скрипт, автоматом проверяющего, висит ли Squid на порту 3128, и если нет, то запускающего его.
Настройка Squid в прозрачном режиме завершена. Вот теперь - все.
Простой DHCP-сервер + прозрачный прокси на Squid
Обновлено: 20.05.2026
Для начала опишу ситуацию, почему я установил у себя на компьютере связку dhcp-сервера и прозрачного прокси на squid. Все дело в том, что мне частенько приходится дома работать с несколькими компьютерами одновременно (что-нить настроить и т.п.), но постоянно каждому компьютеру прописывать ручками ip, а так же прописывать настройки прокси очень не удобно, можешь забыть, что ты уже использовал какой-то ip - поэтому и получаешь конфликты ip-адресов.
Хочу сразу предупредить, что описал лишь только те параметры конфигурационных файлов, которые необходимы для простой работы dhcp-сервера и прокси Squid. Так как этих параметров уйма, предлагаю вам самим с ними поразбираться, а не упрекать меня в том, что я что-то не описал.
Установка DHCP-сервера
1. Устанавливаем dnsmasq
$sudo apt-get install dnsmasq
2. Редактируем файл /etc/dnsmasq.conf
$sudo nano /etc/dnsmasq.conf
3. Ищем закомментированную строку (что то вроде этого):
#interface=eth0
и раскомментируем ее
interface=eth0
при этом не забываем поменять название сетевой карты - eth0 на название вашей сетевой карты, к которой будут конектиться другие компьютеры из вашей сети.
4. Дальше, в этом же файле, раскомментируем или добавляем свою строку: dhcp-range= . К примеру, вот как она выглядит у меня:
dhcp-range=192.168.0.2,192.168.0.15,12h
данная запись означает, что всем компьютерам подключающимся к моей сети, будут автоматически выдаваться ip-адреса, c 192.168.0.2 по 192.168.0.15. И аренда этих адресов будет составлять 12 часов.
5. Перезапускаем сервис dnsmasq:
$sudo /etc/init.d/dnsmasq restart
6. Подключаем в сеть какой-нить компьютер, при этом не забываем поставить ему в сетевых настройках, получение ip-адреса автоматически. Если все верно - то компьютеру присвоится ip-адрес из заданного нами в настройках диапазона.
Установка прозрачного прокси.
1. Устанавливаем squid (и если потребуется, другие нужные пакеты, которые он запросит автоматически):
$sudo apt-get install squid
2. Редактируем файл настроек squid:
$sudo nano /etc/squid/squid.conf
3. Ищем параметр http_port , и выставляем ему следующее значение (к примеру, как у меня):
http_port 3128 transparent
ключевое слово здесь - это transparent, в результате его мы и получим "прозрачный" прокси. А 3128 - это порт для протокола http.
4. В этом же файле ищем параметр visible_hostname и выставляем ему следующее значение:
visible_hostname (название прокси)
где (название прокси) - можете заменить на любое слово или словосочетание. Если вы не заполните данный параметр - squid будет очень сильно ругаться )) 5. Ищем дальше. Теперь ищем параметр acl our_networks заменяем его на такие строки (вот как к примеру у меня):
acl our_networks src 192.168.0.0/255.255.0.0
http_access allow our_networks
Данными строками мы разрешили доступ к прокси для компьютеров из нашей сети 192.168.0.0.
6. Перезапускаем сервис squid:
$sudo /etc/init.d/squid restart
7. Ну и наконец-то завершающий аккорд. Добавим правило перенаправления портов в наш файервол.
$sudo iptables -t nat -A PREROUTING -i eth0 -d ! 192.168.0.0/24 -p tcp -m multiport --dport 80,8080 -j DNAT --to 192.168.0.1:3128
8. Теперь компьютеры в вашей сети смогут выходить в интернет через ваш "прозрачный" прокси, при этом нам нигде не надо прописывать настройки прокси вручную !! Все работает автоматом.
P.S. Чтобы снова, при каждом включении компьютера, не запускать по новой правило для файервола, проделываем следующее:
1. Запускаем правило для файервола:
$sudo iptables -t nat -A PREROUTING -i eth0 -d ! 192.168.0.0/24 -p tcp -m multiport --dport 80,8080 -j DNAT --to 192.168.0.1:3128
2. Сохраняем список всех правил файервола в файл:
$iptables-save /etc/iptables.rules
3. Редактируем файл /etc/network/interfaces
$sudo nano /etc/network/interfaces
и после блока про сетевую карту eth0 (к примеру, у меня так), вставляем строку
pre-up iptables-restore < /etc/iptables.rules
Вот собственно и все ))
Автор: leolik
blog: http://leolik.blogspot.com
email: leolikua at gmail.com
Команды OpenVPN
Обновлено: 18.03.2020
OpenVPN - очень гибкое, удобное, а главное быстрое и безопасное, решение для построения виртуальных частных сетей VPN. В данной статье я попытаюсь наиболее подробно описать основные команды, используемые в OpenVPN.
Синхронизация избранного с помощью Dropbox
Обновлено: 17.03.2020
Вступление
Я в большой степени не сторонник всего "самого-самого". Один из последних среди друзей стал использовать кредитки в интернете, один из последних стал поглядывать во вконтакт и все такое. Поэтому многочисленные социальные сервисы хранения закладок и прочие online фишки проходят до поры до времени мимо меня. Поэтому в этой статейке речь не пойдет о том, например, как прикрутить Google Bookmarks куда-либо. Мы будем делать примитивно и просто: синхронизировать содержимое папки (или файла) избранного. Для примера возьмем Internet Explorer и Windows 7.
Задача: иметь дома и на работе одинаковое избранное, при этом ничего не копируя (например, на флешку или еще куда-либо). Синхронизировать избранное мы будем с помощью Dropbox в качестве online-хранилища и:
- Символьной ссылки (команда
mklinkв Windows) - Allway Sync в качестве простой и без выкрутасов программы синхронизации файлов.
Теория
Dropbox
Для тех, кто не в курсе - Dropbox это веб-сервис, бесплатно предоставляющий 2 Гб для хранения файлов. Сейчас 2 Гб это уже не так и много, но для большинства нужных файлов этого достаточно - я имею ввиду текстовые документы по работе, избранное и пр. не-видео контент. На Dropbox-е можно оплачивать 50 Гб и более, но это уже стоит от $10/месяц.
Работа с Dropbox проста - устанавливаете программу-клиент (есть версии для Windows, Mac и Linux), вводите свой логин/пароль (если их нет, регистрируетесь). Программа спросит вас, какую папку использовать для синхронизации. Все. В дальнейшем просто копируете файлы в эту папку и они доступны для доступа с другого компьютера. Причем есть режим для разрешения доступа к файлам (в папке Public) любому пользователю Интернет (дальше параноикам можно НЕ ЧИТАТЬ!). В общем, все просто. Осталось только мелочь - периодически обновлять содержимое папки Dropbox свежими версиями файлов. Например, если вы хотите иметь общее избранное на нескольких компьютерах, вам надо будет вручную копировать избранное в папку синхронизации Dropbox-а. Как правило, вы будете вспоминать об этом сразу после нажатия кнопки завершения работы на рабочем компьютере в 18:05, т.е. домой вы едете устаревшим.
Предположим, что вы скачали версию для Windows и установили в каталог C:SyncDataDropbox.
Символьные ссылки
Символьная ссылка (также симлинк от англ. Symbolic link, символическая ссылка) — специальный файл в UNIX-подобных операционных системах, для которого в файловой системе не хранится никакой информации, кроме одной текстовой строки. Эта строка трактуется как путь к файлу, который должен быть открыт при попытке обратиться к данной ссылке. Символьная ссылка занимает ровно столько места на файловой системе, сколько требуется для записи её содержимого (нормальный файл занимает как минимум один блок раздела).
Целью ссылки может быть любой объект — например, другая ссылка, или даже несуществующий файл (в последнем случае при попытке открыть его должно выдаваться сообщение об отсутствии файла). Ссылка, указывающая на несуществующий файл, называется висячей.
Практически символьные ссылки используются для более удобной организации структуры файлов на компьютере, так как позволяют одному файлу или каталогу иметь несколько имён и свободны от некоторых ограничений, присущих жёстким ссылкам (последние действуют только в пределах одного раздела и не могут ссылаться на каталоги).
Символьные ссылки в Windows, в отличие от жестких ссылок, могут указывать на файлы и директории в других томах.
Виды символьных ссылок в Windows:
- Символьные связи (junction points) — доступна с Windows 2000 (файловая система NTFS 5). Может указывать только на директории.
Команда —linkd(Microsoft Windows Resource Kit) - Символическая ссылка (symbolic links) — доступна с Windows Vista. Может указывать и на файлы, и на директории.
Команда —mklink
Вот с командой mklink мы и будем работать. Запуск команды возможен с правами администратора. Запуск команды без параметров даст следующий вывод:
Создание символической ссылки. MKLINK [[/D] | [/H] | [/J]] Ссылка Назначение /D Создание символической ссылки на каталог. По умолчанию создается символическая ссылка на файл. /H Создание жесткой связи вместо символической ссылки. /J Создание соединения для каталога. Ссылка Имя новой символической ссылки. Назначение Путь (относительный или абсолютный), на который ссылается новая ссылка.
Нас будет интересовать режим /D - создание символической ссылки на каталог.
mklink совпадет с уже существующей папкой на диске, то команда не будет выполнена. Т.е. если у нас есть папка d:folder1, который мы хотим залинковать в папку c:copy, то если у нас уже есть папка c:copy, команда не выполнится! В таком случае нам надо удалить папку c:copy (или переместить ее в другое место), выполнить команду "mklink /D c:copy d:folder1" и после этого перенести содержимое старой папки c:copy в созданную символьную ссылку c:copy. Звучит трудновато, но как только начнете работать с mklink, сразу поймете!1. Автоматическая синхронизация с помощью символьных ссылок
Важно: метод скорее напоминает костыли в 21 веке - ознакомтесь с комментариями.
Наша задача состоит в том, чтобы при создании/удалении записи в папке "Избранное" на вашем рабочем компьютере эти изменения сразу же отображались бы в Dropbox.
Для начала давайте примем политическое решение: создадим в папке Избранное папку Местное. В эту папку мы будем помещать те ссылки, которые не предназначены для синхронизации. Далее с помощью команды mklink создадим в папке Избранное символьную ссылку с именем Синхронизировать, в которую будем сохранять только те ссылки, которые будут нас приследовать дома и на работе. OK, поехали.
Запускаем cmd. Если вы не администратор, выполняем команду:
runas /user:administrator cmd
Вводим пароль администратора, в новом окне cmd от имени администратора выполняем команду:
C:Windowssystem32>
mklink /D C:UsersUserNameFavoritesСинхронизировать C:SyncDataDropboxСинхронизированноеИзбранное
где:
/D- режим создания символьной ссылки,C:SyncDataDropboxСинхронизированноеИзбранное- имя папки, которую Dropbox будет синхронизировать с сервером Amazon (где, собственно, Dropbox и хранит все, что мы ему отдаем),C:UsersUserNameFavoritesСинхронизировать- символьная ссылка (а по-простому, ярлык-папка), в которую мы будем сохранять все ссылки, которые хотим увидеть на другом компьютере.
Все. Теперь вам надо будет проделать эту несложную процедуру дома. Сохранять все в одну папку я не захотел, все-таки может быть ситуация, когда вам не захочется переносить кое-какие ссылки из домашней коллекции на рабочий компьютер ;)
2. Автоматическая синхронизация с помощью бесплатных программ
Тоже своего рода "костыль" :) Да, не элегантно, не модно. Но - работает.
Например, с помощью Allway Sync. Фактически, просто создаем задачу синхронизации двух каталогов: папки Избранное на компьютере и папки СинхронизированноеИзбранное в Dropbox. Сейчас раздел в разработке (хотя что там разрабатывать? Просто словосочетание красивое) - надо сделать скриншот :) Собственно, все.
В использовании Dropbox есть плюс в том, что им и так часто кто пользуется, а так мы просто немного расширяем его область применения.
Опции sendmail
Обновлено: 20.05.2026
Пакет sendmail имеет ряд параметров, которые позволяют Вам настраивать выполнение ряда задач. Я рассмотрю лишь основные, полный перечень огромен.
Чтобы конфигурировать любые из этих параметров, Вы можете определять их в файле конфигурации m4, что является предпочтительным методом, или вставлять их непосредственно в файл sendmail.cf. Например, если нужно, чтобы sendmail запускал новый процесс для каждого сообщения почты, нужно добавить строку к файлу конфигурации m4:
define(`confSEPARATE_PROC',`true')
Соответствующая запись в файле sendmail.cf:
O ForkEachJob=true
Следующий список описывает общие параметры sendmail m4 и эквиваленты sendmail.cf:
- confMIN_FREE_BLOCKS (MinFreeBlocks)
-
Есть одна проблема с почтовой очередью: она растет. При большом числе писем, она может разрастись настолько, что на диске свободного места уже не будет. Поэтому есть опция, чтобы определить минимальное число дисковых блоков, которые должны быть свободны перед приемом письма (значение по умолчанию 100 блоков). Блоки в разных системах могут иметь разный размер, но обычно кратный 512 байтам.
- confME_TOO (MeToo)
-
При раскрытии псевдонимов отправитель письма может оказаться в списке получателей. Эта опция определяет, получит ли отправитель копию. Имеющие силу значения: "true" и "false" (значение по умолчанию false).
- confMAX_DAEMON_CHILDREN (MaxDaemonChildren)
-
При получении sendmail входящего соединения SMTP с удаленного хоста, для его обработки запускается отдельная копия sendmail. Но память-то у Вашей машины не резиновая! При большом количестве таких подключений кончится все, что угодно. Тем более, sendmail не относится к числу программ с низким потреблением ресурсов. Эта опция позволяет задать максимальное число копий, которые работают одновременно. Если лимит исчерпан, входящие соединения будут отклоняться до завершения работы какой-то копии. Значение по умолчанию: undefined (не определено).
- confSEPARATE_PROC (ForkEachJob)
-
При обработке очереди почты и посылке сообщений sendmail обрабатывает одно сообщение за раз. Когда эта опция включена, sendmail будет порождать по копии для каждого письма. Это особенно полезно, когда имеются некоторые сообщения, которые увязли в очереди потому, что есть проблемы с целевым хостом. (Значение по умолчанию: false).
-
При подключении sendmail выдает приветствие. По умолчанию, это сообщение содержит hostname, имя агента передачи почты, версию sendmail, локальную версию и текущую дату. RFC 821 определяет, что первым словом приветствия должно быть полным доменным именем компьютера, но остальная часть может быть произвольной. Вы можете определять здесь даже макрокоманды sendmail, они будут нормально работать! Единственные люди, которые это сообщение увидят, это администраторы, пытающиеся понять, почему не работает почта у них, и люди, которым интересна настройка Вашего сервера (например, хакеры). Слово "EMSTP" между первым и вторым словами служит сигналом удаленным хостам о поддержке этого протокола (значение по умолчанию: $j Sendmail $v/$Z; $b).
- confSMTP_LOGIN_MSG (SmtpGreetingMessage)
Источник: http://www.linuxsoft.ru/info/lib/lib/nag20/x15220.htm.
Построение файла sendmail.cf
Обновлено: 20.05.2026Когда Вы завершили редактирование файла конфигурации m4, Вы должны его обработать, чтобы построить файл /etc/mail/sendmail.cf. Это делается так:
# m4 /usr/share/sendmail.cf/m4/cf.m4 vstout.uucpsmtp.mc >sendmail.cf
Эта команда вызывает макропроцессор m4 и передает ему имена двух файлов макроопределений. Затем m4 обрабатывает файлы в порядке поступления. Первый файл стандартный шаблон макрокоманд, обеспеченный исходным пакетом sendmail, второй, конечно, является файлом, содержащим наши собственные определения макрокоманд. Вывод команды направлен в файл /etc/mail/sendmail.cf, который является адресатом.
Вы можете теперь запустить sendmail с новой конфигурацией всех параметров.
Источник: http://www.linuxsoft.ru/info/lib/lib/nag20/x14903.htm
Порядок прохождения таблиц и цепочек IPTABLES
Обновлено: 20.05.2026
Порядок прохождения таблиц и цепочек IPTABLES
В этой главе мы рассмотрим порядок прохождения таблиц и цепочек в каждой таблице. Эта информация будет очень важна для вас позднее, когда вы начнете строить свои наборы правил, особенно когда в наборы правил будут включаться такие действия как DNAT, SNAT и конечно же TOS. Источник.
Общие положения
Когда пакет приходит на наш брандмауэр, то он сперва попадает на сетевое устройство, перехватывается соответствующим драйвером и далее передается в ядро. Далее пакет проходит ряд таблиц и затем передается либо локальному приложению, либо переправляется на другую машину. Порядок следования пакета приводится ниже.
Таблица 1. Порядок движения транзитных пакетов
|
Шаг |
Таблица |
Цепочка |
Примечание |
|
1 |
═ |
═ |
Кабель (т.е. Интернет) |
|
2 |
═ |
═ |
Сетевой интерфейс (например, eth0) |
|
3 |
Mangle |
PREROUTING |
Обычно эта цепочка используется для внесения изменений в заголовок пакета, например для изменения битов TOS и пр.. |
|
4 |
Nat |
PREROUTING |
Эта цепочка используется для трансляции сетевых адресов (Destination Network Address Translation). Source Network Address Translation выполняется позднее, в другой цепочке. Любого рода фильтрация в этой цепочке может производиться только в исключительных случаях |
|
5 |
═ |
═ |
Принятие решения о дальнейшей маршрутизации, т.е. в этой точке решается куда пойдет пакет - локальному приложению или на другой узел сети. |
|
6 |
Filter |
FORWARD |
В цепочку FORWARD попадают только те пакеты, которые идут на другой хост Вся фильтрация транзитного трафика должна выполняться здесь. Не забывайте, что через эту цепочку проходит траффик в обоих направлениях, обязательно учитывайте это обстоятельство при написании правил фильтрации. |
|
7 |
Mangle |
FORWARD |
Далее пакет попадает в цепочку FORWARD> таблицы mangle, которая должна использоваться только в исключительных случаях, когда необходимо внести некоторые изменения в заголовок пакета между двумя точками принятия решения о маршрутизации. |
|
8 |
═ |
═ |
Принятие решения о дальнейшей маршрутизации, т.е. в этой точке, к примеру, решается на какой интерфейс пойдет пакет. |
|
9 |
Nat |
POSTROUTING |
Эта цепочка предназначена в первую очередь для Source Network Address Translation. Не используйте ее для фильтрации без особой на то необходимости. Здесь же выполняется и маскировка (Masquerading). |
|
10 |
Mangle |
POSTROUTING |
Эта цепочка предназначена для внесения изменений в заголовок пакета уже после того как принято последнее решение о маршрутизации. |
|
11 |
═ |
═ |
Выходной сетевой интерфейс (например, eth1). |
|
12 |
═ |
═ |
Кабель (пусть будет LAN). |
Как вы можете видеть, пакет проходит несколько этапов, прежде чем он будет передан далее. На каждом из них пакет может быть остановлен, будь то цепочка iptables или что либо еще, но нас главным образом интересует iptables. Заметьте, что нет каких либо цепочек, специфичных для отдельных интерфейсов или чего либо подобного. Цепочку FORWARD проходят ВСЕ пакеты, которые движутся через наш брандмауэр/роутер. Не используйте цепочку INPUT для фильтрации транзитных пакетов, они туда просто не попадают! Через эту цепочку движутся только те пакеты, которые предназначены данному хосту!
А теперь рассмотрим порядок движения пакета, предназначенного локальному процессу/приложению
Таблица 2. Для локального приложения
|
Шаг |
Таблица |
Цепочка |
Примечаниеt |
|
1 |
═ |
═ |
Кабель (т.е. Интернет) |
|
2 |
═ |
═ |
Входной сетевой интерфейс (например, eth0) |
|
3 |
Mangle |
PREROUTING |
Обычно используется для внесения изменений в заголовок пакета, например для установки битов TOS и пр. |
|
4 |
Nat |
PREROUTING |
Преобразование адресов (Destination Network Address Translation). Фильтрация пакетов здесь допускается только в исключительных случаях. |
|
5 |
═ |
═ |
Принятие решения о маршрутизации. |
|
6 |
Mangle |
INPUT |
Пакет попадает в цепочку INPUT таблицы mangle. Здесь внесятся изменения в заголовок пакета перед тем как он будет передан локальному приложению. |
|
7 |
Filter |
INPUT |
Здесь производится фильтрация входящего трафика. Помните, что все входящие пакеты, адресованные нам, проходят через эту цепочку, независимо от того с какого интерфейса они поступили. |
|
8 |
═ |
═ |
Локальный процесс/приложение |
Важно помнить, что на этот раз пакеты идут через цепочку INPUT, а не через FORWARD. И в заключение мы рассмотрим порядок движения пакетов, созданных локальными процессами.
Таблица 3. От локальных процессов
|
Шаг |
Таблица |
Цепочка |
Примечание |
|
1 |
═ |
═ |
Локальный процесс |
|
2 |
Mangle |
OUTPUT |
Здесь производится внесение изменений в заголовок пакета. Фильтрация, выполняемая в этой цепочке, может иметь негативные последствия. |
|
3 |
Nat |
OUTPUT |
Эта цепочка используется для трансляции сетевых адресов (NAT) в пакетах, исходящих от локальных процессов брандмауэра. |
|
4 |
Filter |
OUTPUT |
Здесь фильтруется исходящий траффик. |
|
5 |
═ |
═ |
Принятие решения о маршрутизации. Здесь решается - куда пойдет пакет дальше. |
|
6 |
Nat |
POSTROUTING |
Здесь выполняется Source Network Address Translation (SNAT). Не следует в этой цепочке производить фильтрацию пакетов во избежание нежелательных побочных эффектов. Однако и здесь можно останавливать пакеты, применяя политику по-умолчанию DROP. |
|
7 |
Mangle |
POSTROUTING |
Цепочка POSTROUTING таблицы mangle в основном используется для правил, которые должны вносить изменения в заголовок пакета перед тем, как он покинет брандмауэр, но уже после принятия решения о маршрутизации. В эту цепочку попадают все пакеты, как транзитные, так и созданные локальными процессами брандмауэра. |
|
8 |
═ |
═ |
Сетевой интерфейс (например, eth0) |
|
9 |
═ |
═ |
Кабель (т.е., Internet) |
Теперь мы знаем, что есть три различных варианта прохождения пакетов. Рисунок ниже более наглядно демонстрирует это.
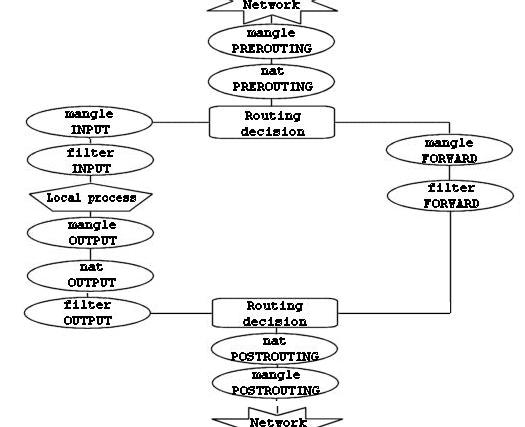
Этот рисунок дает довольно ясное представление о порядке прохождения пакетов через различные цепочки. В первой точке принятия решения о маршрутизации (routing decision) все пакеты, предназначенные данному хосту направляются в цепочку INPUT, остальные - в цепочку FORWARD.
Обратите внимание также на тот факт, что пакеты, с адресом назначения на брандмауэр, могут претерпеть трансляцию сетевого адреса (DNAT) в цепочке PREROUTING таблицы nat и соответственно дальнейшая маршрутизация в первой точке будет выполняться в зависимости от произведенных изменений.

Принимаю заказы на настройку серверов, mikrotik и других роутеров, точек доступа, nginx и т.п. В пределах Санкт-Петербурга возможен выезд к заказчику. См. контакты.
 Squid
3proxy
VPN
Шифрование
Почтовый сервер
Mikrotik
Настройка сервера
Защита почты
Резервное копирование
Групповые политики
java
WDS
IPFW
SELinux
kvm
OpenVPN
Виртуальные машины
libvirt
Mobile
systemd
Samba
WiFi
firewalld
Lightsquid
Remote desktop
NAT
Iptables
Нейронные сети
python
Docker
Софт
Удаление данных
Безопасность
Winbox
User agent
Privacy
Онлайн сервисы
Передача данных
Хостинг
Dovecot
Postfix
VPN сервер
RRDTool
sendmail
Rsync
Linux
Настройка прокси
Система
Windows
Синхронизация
Облако
fail2ban
SSH
LetsEncrypt
FreeBSD
Squid
3proxy
VPN
Шифрование
Почтовый сервер
Mikrotik
Настройка сервера
Защита почты
Резервное копирование
Групповые политики
java
WDS
IPFW
SELinux
kvm
OpenVPN
Виртуальные машины
libvirt
Mobile
systemd
Samba
WiFi
firewalld
Lightsquid
Remote desktop
NAT
Iptables
Нейронные сети
python
Docker
Софт
Удаление данных
Безопасность
Winbox
User agent
Privacy
Онлайн сервисы
Передача данных
Хостинг
Dovecot
Postfix
VPN сервер
RRDTool
sendmail
Rsync
Linux
Настройка прокси
Система
Windows
Синхронизация
Облако
fail2ban
SSH
LetsEncrypt
FreeBSD


Последние комментарии
Популярно:
Разделы статей:
Подскажите. подключение с ПК все работает все ок. Делал по вашей мурзилке.
Но при подключе...